mlflow.pytorch
The mlflow.pytorch module provides an API for logging and loading PyTorch models. This module
exports PyTorch models with the following flavors:
- PyTorch (native) format
This is the main flavor that can be loaded back into PyTorch.
mlflow.pyfuncProduced for use by generic pyfunc-based deployment tools and batch inference.
-
mlflow.pytorch.autolog(log_every_n_epoch=1, log_models=True, disable=False, exclusive=False, disable_for_unsupported_versions=False, silent=False, registered_model_name=None)[source] Note
Autologging is known to be compatible with the following package versions:
1.0.5<=pytorch-lightning<=1.5.10. Autologging may not succeed when used with package versions outside of this range.Enables (or disables) and configures autologging from PyTorch Lightning to MLflow.
Autologging is performed when you call the fit method of pytorch_lightning.Trainer().
Explore the complete PyTorch MNIST for an expansive example with implementation of additional lightening steps.
Note: Autologging is only supported for PyTorch Lightning models, i.e., models that subclass pytorch_lightning.LightningModule. In particular, autologging support for vanilla PyTorch models that only subclass torch.nn.Module is not yet available.
- Parameters
log_every_n_epoch – If specified, logs metrics once every n epochs. By default, metrics are logged after every epoch.
log_models – If
True, trained models are logged as MLflow model artifacts. IfFalse, trained models are not logged.disable – If
True, disables the PyTorch Lightning autologging integration. IfFalse, enables the PyTorch Lightning autologging integration.exclusive – If
True, autologged content is not logged to user-created fluent runs. IfFalse, autologged content is logged to the active fluent run, which may be user-created.disable_for_unsupported_versions – If
True, disable autologging for versions of pytorch and pytorch-lightning that have not been tested against this version of the MLflow client or are incompatible.silent – If
True, suppress all event logs and warnings from MLflow during PyTorch Lightning autologging. IfFalse, show all events and warnings during PyTorch Lightning autologging.registered_model_name – If given, each time a model is trained, it is registered as a new model version of the registered model with this name. The registered model is created if it does not already exist.
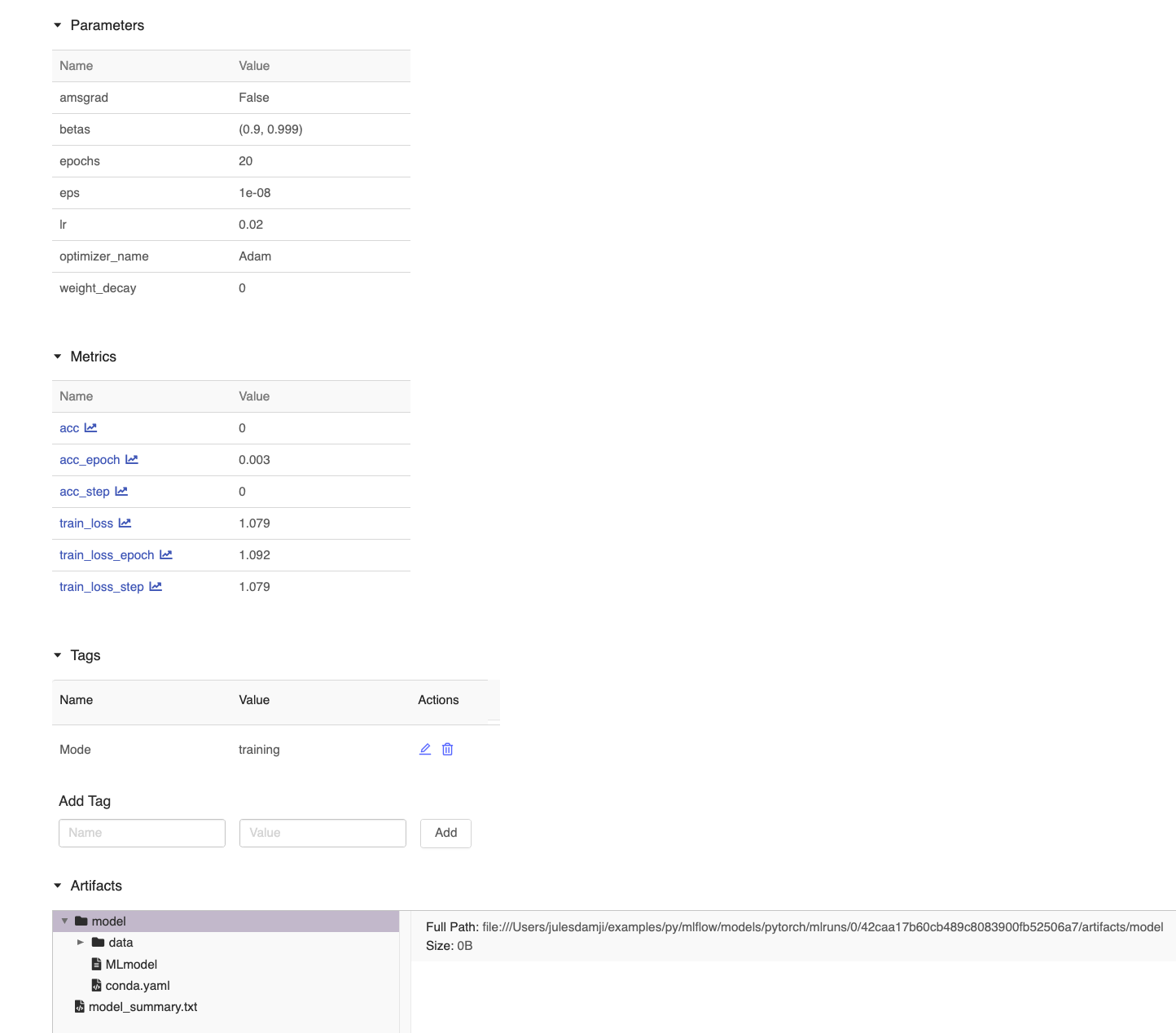
import os import pytorch_lightning as pl import torch from torch.nn import functional as F from torch.utils.data import DataLoader from torchvision import transforms from torchvision.datasets import MNIST try: from torchmetrics.functional import accuracy except ImportError: from pytorch_lightning.metrics.functional import accuracy import mlflow.pytorch from mlflow.tracking import MlflowClient # For brevity, here is the simplest most minimal example with just a training # loop step, (no validation, no testing). It illustrates how you can use MLflow # to auto log parameters, metrics, and models. class MNISTModel(pl.LightningModule): def __init__(self): super(MNISTModel, self).__init__() self.l1 = torch.nn.Linear(28 * 28, 10) def forward(self, x): return torch.relu(self.l1(x.view(x.size(0), -1))) def training_step(self, batch, batch_nb): x, y = batch loss = F.cross_entropy(self(x), y) acc = accuracy(loss, y) # Use the current of PyTorch logger self.log("train_loss", loss, on_epoch=True) self.log("acc", acc, on_epoch=True) return loss def configure_optimizers(self): return torch.optim.Adam(self.parameters(), lr=0.02) def print_auto_logged_info(r): tags = {k: v for k, v in r.data.tags.items() if not k.startswith("mlflow.")} artifacts = [f.path for f in MlflowClient().list_artifacts(r.info.run_id, "model")] print("run_id: {}".format(r.info.run_id)) print("artifacts: {}".format(artifacts)) print("params: {}".format(r.data.params)) print("metrics: {}".format(r.data.metrics)) print("tags: {}".format(tags)) # Initialize our model mnist_model = MNISTModel() # Initialize DataLoader from MNIST Dataset train_ds = MNIST(os.getcwd(), train=True, download=True, transform=transforms.ToTensor()) train_loader = DataLoader(train_ds, batch_size=32) # Initialize a trainer trainer = pl.Trainer(max_epochs=20, progress_bar_refresh_rate=20) # Auto log all MLflow entities mlflow.pytorch.autolog() # Train the model with mlflow.start_run() as run: trainer.fit(mnist_model, train_loader) # fetch the auto logged parameters and metrics print_auto_logged_info(mlflow.get_run(run_id=run.info.run_id))
run_id: 42caa17b60cb489c8083900fb52506a7 artifacts: ['model/MLmodel', 'model/conda.yaml', 'model/data'] params: {'betas': '(0.9, 0.999)', 'weight_decay': '0', 'epochs': '20', 'eps': '1e-08', 'lr': '0.02', 'optimizer_name': 'Adam', ' amsgrad': 'False'} metrics: {'acc_step': 0.0, 'train_loss_epoch': 1.0917967557907104, 'train_loss_step': 1.0794280767440796, 'train_loss': 1.0794280767440796, 'acc_epoch': 0.0033333334140479565, 'acc': 0.0} tags: {'Mode': 'training'}
-
mlflow.pytorch.get_default_conda_env()[source] - Returns
The default Conda environment as a dictionary for MLflow Models produced by calls to
save_model()andlog_model().
import mlflow.pytorch # Log PyTorch model with mlflow.start_run() as run: mlflow.pytorch.log_model(model, "model") # Fetch the associated conda environment env = mlflow.pytorch.get_default_conda_env() print("conda env: {}".format(env))
-
mlflow.pytorch.get_default_pip_requirements()[source] - Returns
A list of default pip requirements for MLflow Models produced by this flavor. Calls to
save_model()andlog_model()produce a pip environment that, at minimum, contains these requirements.
-
mlflow.pytorch.load_model(model_uri, dst_path=None, **kwargs)[source] Load a PyTorch model from a local file or a run.
- Parameters
model_uri –
The location, in URI format, of the MLflow model, for example:
/Users/me/path/to/local/modelrelative/path/to/local/models3://my_bucket/path/to/modelruns:/<mlflow_run_id>/run-relative/path/to/modelmodels:/<model_name>/<model_version>models:/<model_name>/<stage>
For more information about supported URI schemes, see Referencing Artifacts.
dst_path – The local filesystem path to which to download the model artifact. This directory must already exist. If unspecified, a local output path will be created.
kwargs – kwargs to pass to
torch.loadmethod.
- Returns
A PyTorch model.
import torch import mlflow.pytorch # Class defined here class LinearNNModel(torch.nn.Module): ... # Initialize our model, criterion and optimizer ... # Training loop ... # Log the model with mlflow.start_run() as run: mlflow.pytorch.log_model(model, "model") # Inference after loading the logged model model_uri = "runs:/{}/model".format(run.info.run_id) loaded_model = mlflow.pytorch.load_model(model_uri) for x in [4.0, 6.0, 30.0]: X = torch.Tensor([[x]]) y_pred = loaded_model(X) print("predict X: {}, y_pred: {:.2f}".format(x, y_pred.data.item()))
-
mlflow.pytorch.load_state_dict(state_dict_uri, **kwargs)[source] Note
Experimental: This method may change or be removed in a future release without warning.
Load a state_dict from a local file or a run.
- Parameters
state_dict_uri –
The location, in URI format, of the state_dict, for example:
/Users/me/path/to/local/state_dictrelative/path/to/local/state_dicts3://my_bucket/path/to/state_dictruns:/<mlflow_run_id>/run-relative/path/to/state_dict
For more information about supported URI schemes, see Referencing Artifacts.
kwargs – kwargs to pass to
torch.load.
- Returns
A state_dict
-
mlflow.pytorch.log_model(pytorch_model, artifact_path, conda_env=None, code_paths=None, pickle_module=None, registered_model_name=None, signature: Optional[mlflow.models.signature.ModelSignature] = None, input_example: Optional[Union[pandas.core.frame.DataFrame, numpy.ndarray, dict, list, scipy.sparse.csr.csr_matrix, scipy.sparse.csc.csc_matrix]] = None, await_registration_for=300, requirements_file=None, extra_files=None, pip_requirements=None, extra_pip_requirements=None, **kwargs)[source] Log a PyTorch model as an MLflow artifact for the current run.
Warning
Log the model with a signature to avoid inference errors. If the model is logged without a signature, the MLflow Model Server relies on the default inferred data type from NumPy. However, PyTorch often expects different defaults, particularly when parsing floats. You must include the signature to ensure that the model is logged with the correct data type so that the MLflow model server can correctly provide valid input.
- Parameters
pytorch_model –
PyTorch model to be saved. Can be either an eager model (subclass of
torch.nn.Module) or scripted model prepared viatorch.jit.scriptortorch.jit.trace.The model accept a single
torch.FloatTensoras input and produce a single output tensor.If saving an eager model, any code dependencies of the model’s class, including the class definition itself, should be included in one of the following locations:
The package(s) listed in the model’s Conda environment, specified by the
conda_envparameter.One or more of the files specified by the
code_pathsparameter.
artifact_path – Run-relative artifact path.
conda_env –
Either a dictionary representation of a Conda environment or the path to a conda environment yaml file. If provided, this describes the environment this model should be run in. At minimum, it should specify the dependencies contained in
get_default_conda_env(). IfNone, a conda environment with pip requirements inferred bymlflow.models.infer_pip_requirements()is added to the model. If the requirement inference fails, it falls back to usingget_default_pip_requirements(). pip requirements fromconda_envare written to a piprequirements.txtfile and the full conda environment is written toconda.yaml. The following is an example dictionary representation of a conda environment:{ "name": "mlflow-env", "channels": ["conda-forge"], "dependencies": [ "python=3.7.0", { "pip": [ "torch==x.y.z" ], }, ], }
code_paths – A list of local filesystem paths to Python file dependencies (or directories containing file dependencies). These files are prepended to the system path when the model is loaded.
pickle_module – The module that PyTorch should use to serialize (“pickle”) the specified
pytorch_model. This is passed as thepickle_moduleparameter totorch.save(). By default, this module is also used to deserialize (“unpickle”) the PyTorch model at load time.registered_model_name – If given, create a model version under
registered_model_name, also creating a registered model if one with the given name does not exist.signature –
ModelSignaturedescribes model input and outputSchema. The model signature can beinferredfrom datasets with valid model input (e.g. the training dataset with target column omitted) and valid model output (e.g. model predictions generated on the training dataset), for example:from mlflow.models.signature import infer_signature train = df.drop_column("target_label") predictions = ... # compute model predictions signature = infer_signature(train, predictions)
input_example – Input example provides one or several instances of valid model input. The example can be used as a hint of what data to feed the model. The given example can be a Pandas DataFrame where the given example will be serialized to json using the Pandas split-oriented format, or a numpy array where the example will be serialized to json by converting it to a list. Bytes are base64-encoded.
await_registration_for – Number of seconds to wait for the model version to finish being created and is in
READYstatus. By default, the function waits for five minutes. Specify 0 or None to skip waiting.requirements_file –
Warning
requirements_filehas been deprecated. Please usepip_requirementsinstead.A string containing the path to requirements file. Remote URIs are resolved to absolute filesystem paths. For example, consider the following
requirements_filestring:requirements_file = "s3://my-bucket/path/to/my_file"
In this case, the
"my_file"requirements file is downloaded from S3. IfNone, no requirements file is added to the model.extra_files –
A list containing the paths to corresponding extra files. Remote URIs are resolved to absolute filesystem paths. For example, consider the following
extra_fileslist -- extra_files = [“s3://my-bucket/path/to/my_file1”,
”s3://my-bucket/path/to/my_file2”]
In this case, the
"my_file1 & my_file2"extra file is downloaded from S3.If
None, no extra files are added to the model.pip_requirements – Either an iterable of pip requirement strings (e.g.
["torch", "-r requirements.txt", "-c constraints.txt"]) or the string path to a pip requirements file on the local filesystem (e.g."requirements.txt"). If provided, this describes the environment this model should be run in. IfNone, a default list of requirements is inferred bymlflow.models.infer_pip_requirements()from the current software environment. If the requirement inference fails, it falls back to usingget_default_pip_requirements(). Both requirements and constraints are automatically parsed and written torequirements.txtandconstraints.txtfiles, respectively, and stored as part of the model. Requirements are also written to thepipsection of the model’s conda environment (conda.yaml) file.extra_pip_requirements –
Either an iterable of pip requirement strings (e.g.
["pandas", "-r requirements.txt", "-c constraints.txt"]) or the string path to a pip requirements file on the local filesystem (e.g."requirements.txt"). If provided, this describes additional pip requirements that are appended to a default set of pip requirements generated automatically based on the user’s current software environment. Both requirements and constraints are automatically parsed and written torequirements.txtandconstraints.txtfiles, respectively, and stored as part of the model. Requirements are also written to thepipsection of the model’s conda environment (conda.yaml) file.Warning
The following arguments can’t be specified at the same time:
conda_envpip_requirementsextra_pip_requirements
This example demonstrates how to specify pip requirements using
pip_requirementsandextra_pip_requirements.kwargs – kwargs to pass to
torch.savemethod.
- Returns
A
ModelInfoinstance that contains the metadata of the logged model.
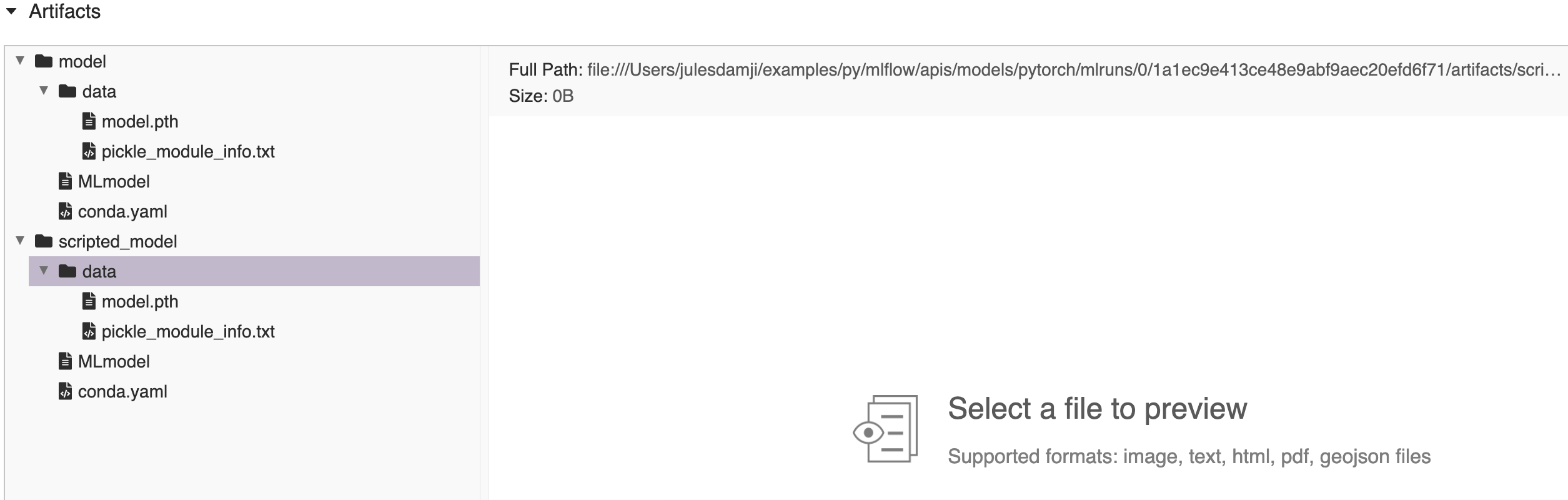
import numpy as np import torch import mlflow.pytorch class LinearNNModel(torch.nn.Module): def __init__(self): super(LinearNNModel, self).__init__() self.linear = torch.nn.Linear(1, 1) # One in and one out def forward(self, x): y_pred = self.linear(x) return y_pred def gen_data(): # Example linear model modified to use y = 2x # from https://github.com/hunkim/PyTorchZeroToAll # X training data, y labels X = torch.arange(1.0, 25.0).view(-1, 1) y = torch.from_numpy(np.array([x * 2 for x in X])).view(-1, 1) return X, y # Define model, loss, and optimizer model = LinearNNModel() criterion = torch.nn.MSELoss() optimizer = torch.optim.SGD(model.parameters(), lr=0.001) # Training loop epochs = 250 X, y = gen_data() for epoch in range(epochs): # Forward pass: Compute predicted y by passing X to the model y_pred = model(X) # Compute the loss loss = criterion(y_pred, y) # Zero gradients, perform a backward pass, and update the weights. optimizer.zero_grad() loss.backward() optimizer.step() # Log the model with mlflow.start_run() as run: mlflow.pytorch.log_model(model, "model") # convert to scripted model and log the model scripted_pytorch_model = torch.jit.script(model) mlflow.pytorch.log_model(scripted_pytorch_model, "scripted_model") # Fetch the logged model artifacts print("run_id: {}".format(run.info.run_id)) for artifact_path in ["model/data", "scripted_model/data"]: artifacts = [f.path for f in MlflowClient().list_artifacts(run.info.run_id, artifact_path)] print("artifacts: {}".format(artifacts))
run_id: 1a1ec9e413ce48e9abf9aec20efd6f71 artifacts: ['model/data/model.pth', 'model/data/pickle_module_info.txt'] artifacts: ['scripted_model/data/model.pth', 'scripted_model/data/pickle_module_info.txt']
-
mlflow.pytorch.log_state_dict(state_dict, artifact_path, **kwargs)[source] Note
Experimental: This method may change or be removed in a future release without warning.
Log a state_dict as an MLflow artifact for the current run.
Warning
This function just logs a state_dict as an artifact and doesn’t generate an MLflow Model.
- Parameters
state_dict – state_dict to be saved.
artifact_path – Run-relative artifact path.
kwargs – kwargs to pass to
torch.save.
# Log a model as a state_dict with mlflow.start_run(): state_dict = model.state_dict() mlflow.pytorch.log_state_dict(state_dict, artifact_path="model") # Log a checkpoint as a state_dict with mlflow.start_run(): state_dict = { "model": model.state_dict(), "optimizer": optimizer.state_dict(), "epoch": epoch, "loss": loss, } mlflow.pytorch.log_state_dict(state_dict, artifact_path="checkpoint")
-
mlflow.pytorch.save_model(pytorch_model, path, conda_env=None, mlflow_model=None, code_paths=None, pickle_module=None, signature: Optional[mlflow.models.signature.ModelSignature] = None, input_example: Optional[Union[pandas.core.frame.DataFrame, numpy.ndarray, dict, list, scipy.sparse.csr.csr_matrix, scipy.sparse.csc.csc_matrix]] = None, requirements_file=None, extra_files=None, pip_requirements=None, extra_pip_requirements=None, **kwargs)[source] Save a PyTorch model to a path on the local file system.
- Parameters
pytorch_model –
PyTorch model to be saved. Can be either an eager model (subclass of
torch.nn.Module) or scripted model prepared viatorch.jit.scriptortorch.jit.trace.The model accept a single
torch.FloatTensoras input and produce a single output tensor.If saving an eager model, any code dependencies of the model’s class, including the class definition itself, should be included in one of the following locations:
The package(s) listed in the model’s Conda environment, specified by the
conda_envparameter.One or more of the files specified by the
code_pathsparameter.
path – Local path where the model is to be saved.
conda_env –
Either a dictionary representation of a Conda environment or the path to a conda environment yaml file. If provided, this describes the environment this model should be run in. At minimum, it should specify the dependencies contained in
get_default_conda_env(). IfNone, a conda environment with pip requirements inferred bymlflow.models.infer_pip_requirements()is added to the model. If the requirement inference fails, it falls back to usingget_default_pip_requirements(). pip requirements fromconda_envare written to a piprequirements.txtfile and the full conda environment is written toconda.yaml. The following is an example dictionary representation of a conda environment:{ "name": "mlflow-env", "channels": ["conda-forge"], "dependencies": [ "python=3.7.0", { "pip": [ "torch==x.y.z" ], }, ], }
mlflow_model –
mlflow.models.Modelthis flavor is being added to.code_paths – A list of local filesystem paths to Python file dependencies (or directories containing file dependencies). These files are prepended to the system path when the model is loaded.
pickle_module – The module that PyTorch should use to serialize (“pickle”) the specified
pytorch_model. This is passed as thepickle_moduleparameter totorch.save(). By default, this module is also used to deserialize (“unpickle”) the PyTorch model at load time.signature –
ModelSignaturedescribes model input and outputSchema. The model signature can beinferredfrom datasets with valid model input (e.g. the training dataset with target column omitted) and valid model output (e.g. model predictions generated on the training dataset), for example:from mlflow.models.signature import infer_signature train = df.drop_column("target_label") predictions = ... # compute model predictions signature = infer_signature(train, predictions)
input_example – Input example provides one or several instances of valid model input. The example can be used as a hint of what data to feed the model. The given example can be a Pandas DataFrame where the given example will be serialized to json using the Pandas split-oriented format, or a numpy array where the example will be serialized to json by converting it to a list. Bytes are base64-encoded.
requirements_file –
Warning
requirements_filehas been deprecated. Please usepip_requirementsinstead.A string containing the path to requirements file. Remote URIs are resolved to absolute filesystem paths. For example, consider the following
requirements_filestring:requirements_file = "s3://my-bucket/path/to/my_file"
In this case, the
"my_file"requirements file is downloaded from S3. IfNone, no requirements file is added to the model.extra_files –
A list containing the paths to corresponding extra files. Remote URIs are resolved to absolute filesystem paths. For example, consider the following
extra_fileslist -- extra_files = [“s3://my-bucket/path/to/my_file1”,
”s3://my-bucket/path/to/my_file2”]
In this case, the
"my_file1 & my_file2"extra file is downloaded from S3.If
None, no extra files are added to the model.pip_requirements – Either an iterable of pip requirement strings (e.g.
["torch", "-r requirements.txt", "-c constraints.txt"]) or the string path to a pip requirements file on the local filesystem (e.g."requirements.txt"). If provided, this describes the environment this model should be run in. IfNone, a default list of requirements is inferred bymlflow.models.infer_pip_requirements()from the current software environment. If the requirement inference fails, it falls back to usingget_default_pip_requirements(). Both requirements and constraints are automatically parsed and written torequirements.txtandconstraints.txtfiles, respectively, and stored as part of the model. Requirements are also written to thepipsection of the model’s conda environment (conda.yaml) file.extra_pip_requirements –
Either an iterable of pip requirement strings (e.g.
["pandas", "-r requirements.txt", "-c constraints.txt"]) or the string path to a pip requirements file on the local filesystem (e.g."requirements.txt"). If provided, this describes additional pip requirements that are appended to a default set of pip requirements generated automatically based on the user’s current software environment. Both requirements and constraints are automatically parsed and written torequirements.txtandconstraints.txtfiles, respectively, and stored as part of the model. Requirements are also written to thepipsection of the model’s conda environment (conda.yaml) file.Warning
The following arguments can’t be specified at the same time:
conda_envpip_requirementsextra_pip_requirements
This example demonstrates how to specify pip requirements using
pip_requirementsandextra_pip_requirements.kwargs – kwargs to pass to
torch.savemethod.
import os import torch import mlflow.pytorch # Class defined here class LinearNNModel(torch.nn.Module): ... # Initialize our model, criterion and optimizer ... # Training loop ... # Save PyTorch models to current working directory with mlflow.start_run() as run: mlflow.pytorch.save_model(model, "model") # Convert to a scripted model and save it scripted_pytorch_model = torch.jit.script(model) mlflow.pytorch.save_model(scripted_pytorch_model, "scripted_model") # Load each saved model for inference for model_path in ["model", "scripted_model"]: model_uri = "{}/{}".format(os.getcwd(), model_path) loaded_model = mlflow.pytorch.load_model(model_uri) print("Loaded {}:".format(model_path)) for x in [6.0, 8.0, 12.0, 30.0]: X = torch.Tensor([[x]]) y_pred = loaded_model(X) print("predict X: {}, y_pred: {:.2f}".format(x, y_pred.data.item())) print("--")
-
mlflow.pytorch.save_state_dict(state_dict, path, **kwargs)[source] Note
Experimental: This method may change or be removed in a future release without warning.
Save a state_dict to a path on the local file system
- Parameters
state_dict – state_dict to be saved.
path – Local path where the state_dict is to be saved.
kwargs – kwargs to pass to
torch.save.