Question Generation For Retrieval Evaluation
MLflow provides an advanced framework for constructing Retrieval-Augmented Generation (RAG) models. RAG is a cutting edge approach that combines the strengths of retrieval models (a model that chooses and ranks relevant chunks of a document based on the user’s question) and generative models. It effectively merges the capabilities of searching and generating text to provide responses that are contextually relevant and coherent, allowing the generated text to make reference to existing documents. RAG leverges the retriever to find context documents, and this novel approach has revolutionized various NLP tasks.
Naturally, we want to be able to evaluate this retriever system for the RAG model to compare and judge its performance. To evaluate a retriever system, we would first need a test set of questions on the documents. These questions need to be diverse, relevant, and coherent. Manually generating questions may be challenging because it first requires you to understand the documents, and spend lots of time coming up with questions for them.
We want to make this process simpler by utilizing an LLM to generate questions for this test set. This tutorial will walk through how to generate the questions and how to analyze the diversity and relevance of the questions.
Step 1: Install and Load Packages
[ ]:
import os
from langchain.docstore.document import Document
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.docstore.document import Document
import openai
# For scraping
import requests
import pandas as pd
from bs4 import BeautifulSoup
# For data analysis and visualization
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
import pandas as pd
import numpy as np
import random
Step 2: Set OpenAI Key
The question generation system can be done using any LLM. We chose to use OpenAI here, so we will need their API key.
[ ]:
openai.api_key = "<redacted>"
os.environ["OPENAI_API_KEY"] = "<redacted>"
Step 3: Decide on chunk size and number of questions per chunk
[ ]:
CHUNK_SIZE = 1500
QUESTIONS_PER_CHUNK = 5
NUM_DOCUMENTS = 40 # Number of scraped chunks to use
Step 4: Get Document Data
We scrape the documents from the Mlflow website to use to generate questions.
[ ]:
page = requests.get("https://mlflow.org/docs/latest/index.html")
soup = BeautifulSoup(page.content, "html.parser")
mainLocation = "https://mlflow.org/docs/latest/"
header = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Accept-Language": "en-US,en;q=0.8",
"Connection": "keep-alive",
}
data = []
for a_link in soup.find_all("a"):
document_url = mainLocation + a_link["href"]
page = requests.get(document_url, headers=header)
soup = BeautifulSoup(page.content, "html.parser")
file_to_store = a_link.get("href").split("/")[-1]
if soup.find("div", {"class": "rst-content"}):
data.append(
[file_to_store, soup.find("div", {"class": "rst-content"}).text.replace("\n", " ")]
)
df = pd.DataFrame(data, columns=["source", "text"])
df.head(3)
| source | text | |
|---|---|---|
| 0 | what-is-mlflow.html | Documentation What is MLflow? What i... |
| 1 | quickstart.html | Documentation Quickstart: Install MLflow, ... |
| 2 | quickstart_mlops.html | Documentation Quickstart: Compare runs, ch... |
Step 5: Load Document Data
We want to generate questions based on a set of documents. Here, we load the documents as Langchain Documents and utilize their embedding models. Through Langchain Documents, each document is broken down into a “chunk”, which is a snippet of the text.
[ ]:
text_splitter = CharacterTextSplitter(chunk_size=CHUNK_SIZE, separator=" ")
documents = []
for index, page in df.iterrows():
chunks = text_splitter.split_text(page[1])
for chunk in chunks:
documents.append(Document(page_content=chunk))
print(documents[0])
Step 6: Generate Questions
The goal here is to generate questions that are coherant and contextually relevant to their respective document chunk. You can use any LLM, but in this tutorial we chose to generate the list of questions with OpenAI GPT3.5. We also utilize prompt engineering to produce better quality questions, as we found it to be a simple and effective way to improve the responses. In particular, we found two changes to be helpful: - Better quality questions were produced if you ask the model for multiple questions per chunk rather than just one. This may be because it can ensure local diversity, better formatting, and have an implicit understanding that you are trying to get a list of questions. - We observed that some questions reference the document without explaining what it is referencing, hence we include this in the prompt explicitly to help with this.
[ ]:
queries = []
for doc in documents[:NUM_DOCUMENTS]:
chunk = doc.page_content
chunks.append(chunk)
params = {
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "user",
"content": f"{chunk}.\n Please generate {QUESTIONS_PER_CHUNK} questions based on the above document. The questions should be diverse and ask for different aspects of the document. Don't give vague references to the document without description. Split each question with a newline",
}
],
}
response = openai.ChatCompletion.create(**params)
response_queries = response.choices[0].message.content
question_list = []
for q in response_queries.splitlines():
q = " ".join(q.split()[1:])
question_list.append(q)
queries.append({"chunk": chunk, "questions": question_list})
print(queries[0])
Quality Analysis of Questions Generated (Optional)
If you would like to compare quality of questions generated across different prompts, we can analyze the quality of questions manually and in aggregate. We want to evaluate questions along two dimensions - their diversity and relevance.
Note: There isn’t a well-defined way to analyze the quality of generated questions, so this is just one approach you can take to gain insight into how diverse and relevant your generated questions are.
Evaluating Diversity of Questions
Diversity of questions is important because we want questions to cover the majority of the document content. In addition, we want to be able to evaluate the retriever with different forms of questioning. We want to be able to have harder questions and easier questions. All of these are not straightforward to analyze, and we decided to analyze its through question length and latent space embeddings.
[ ]:
# Get all the questions in a list
questions = []
for query in queries:
questions += query["questions"]
Length
Length gives a sense of how diverse the questions are. Some questions may be wordy while others are straight to the point. It also allows us to identify problems with the question generated. For example, you may identify some questions to have a length of 0.
[ ]:
# Length
question_len = pd.DataFrame([len(q) for q in questions], columns=["length"])
question_len.hist(bins=100)
plt.title("Histogram of Question Lengths")
plt.xlabel("Question Length")
plt.ylabel("Frequency")
plt.show()
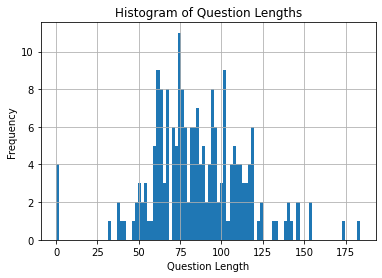
In addition to visual representation, we also want to look at more concrete percentile values.
[ ]:
# Calculating percentile values
p10 = int(question_len["length"].quantile(0.10))
p90 = int(question_len["length"].quantile(0.90))
print("p10-p90 range is", p90 - p10)
We noticed that the short queries are all empty strings, and hence we need to filter for this.
[ ]:
[q for q in questions if len(q) < 5]
There are also a couple queries that are longer than normal. However, these seem fine.
[ ]:
[q for q in questions if len(q) > 160]
Latent Space
Latent space embeddings contain semantic information about the question. This can be used to evaluate the diversity and the difference between two questions semantically. To do so, we will need to map the high dimensional space to a lower dimensional space. We utilize PCA and TSNE to map the embeddings into a 2-dimensional space for visualization.
[ ]:
# post process to remove empty questions
questions_to_embed = [q for q in questions if len(q) > 0]
We append 5 benchmark queries to help visualize how diverse the questions are. The first four of these questions are semantically similar and all asking about Mlflow, while the last is different and refers to spark and model registry.
[ ]:
benchmark_questions = [
"What is MLflow?",
"What is Mlflow about?",
"Tell me about Mlflow Tracking",
"How does Mlflow work?",
"How is spark used in model registry?",
]
questions_to_embed = questions_to_embed + benchmark_questions
We apply PCA to reduce the embedding dimensions to 50 before applying TSNE to reduce it to 2 dimensions, as recommended by sklearn due to the computational complexity of TSNE.
[ ]:
# Apply embeddings
embeddings = OpenAIEmbeddings()
question_embeddings = embeddings.embed_documents(questions_to_embed)
# PCA on embeddings to reduce to 50-dim
pca = PCA(n_components=50)
question_embeddings_50 = pca.fit_transform(question_embeddings)
# TSNE on embeddings to reduce to 2-dim
tsne = TSNE(n_components=2)
lower_dim_embeddings = tsne.fit_transform(question_embeddings_50)
Now that we have 2-dimensional embeddings representing the semantics of the question, we can visualize it with a scatter plot, differentiating the generated questions and the benchmark questions.
[ ]:
labels = np.concatenate(
[
np.full(len(lower_dim_embeddings) - len(benchmark_questions), "generated"),
np.full(len(benchmark_questions), "benchmark"),
]
)
data = pd.DataFrame(
{"x": lower_dim_embeddings[:, 0], "y": lower_dim_embeddings[:, 1], "label": labels}
)
sns.scatterplot(data=data, x="x", y="y", hue="label");
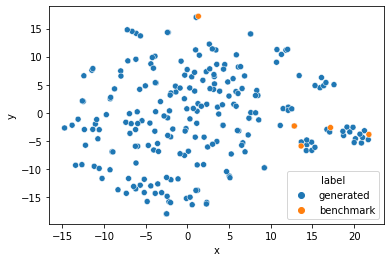
Observe that within the orange points on the scatter plot, there is one point that is further than the others. That is the unique benchmark question about Spark and Model Registry. This plot gives a sense of the diversity of the questions generated.
Evaluate Document Relevance
Another important axis to consider is how relevant the questions are to the document we provided. We want to understand whether the questions generated by the LLM is actually referring to our provided text, or whether it is hallucinating irrelevant questions. We will evaluate relevance by first manually checking certain questions against their document chunk. Then, we define a measure of relevance to analyze it quantitatively.
Manual Checking of Document Relevance
Manual qualitative check of whether the questions are relevant to the document.
[ ]:
samples = 3 # num of chunks we want to observe
for query in random.sample(queries, samples):
print("Chunk:", query["chunk"])
for q in query["questions"]:
print("Question:", q)
print("-" * 80) # delimiter
Embeddings Cosine Similarity
The embedding of the chunk and query is placed in the same latent space, and the retriever model would extract similar chunk embeddings to a query embedding. Hence, relevance for the retriever is defined by the distance of embeddings in this latent space.
Cosine similarity is a measure of vector similarity, and can be used to determine the distance of embeddings between the chunk and the query. It is a distance metric that approaches 1 when the question and chunk are similar, and becomes 0 when they are different.
We can use the cosine similarity score directly to measure the relevancy. However, if we just have a cosine similarity score, it is not interpretable without something to compare it to. Hence, we define relative question relevance as:
This relative question relevance can measure how much more relevant a question generated from the chunk is compared to a question generated by another chunk in this dataset. It would give a score of above 1 if the question generated from the chunk is more relevant and a score below if its not. We can then use this score to identify any irrelevant questions generated.
[ ]:
embedded_queries = []
for query in queries:
embedded_query = {
"chunk": np.squeeze(embeddings.embed_documents([query["chunk"]])),
"questions": embeddings.embed_documents(
[q for q in query["questions"] if len(q) > 0]
), # embedding cant take empty strings
}
embedded_queries.append(embedded_query)
[ ]:
def cossim(x, y):
return np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
question_relevance = []
for i, query in enumerate(embedded_queries):
for q_index, question_emb in enumerate(query["questions"]):
# generate cosine similarity for the chunk the question is generated from
chunk_sim = cossim(question_emb, query["chunk"])
# generate average cosine similarity between chunk and irrelevant questions
avg_irrelevant_cossim = []
for j, other_query in enumerate(embedded_queries):
if i != j:
# supposedly irrelevant questions to the chunk.
for q_emb in other_query["questions"]:
avg_irrelevant_cossim.append(cossim(q_emb, query["chunk"]))
other_sim = np.average(avg_irrelevant_cossim)
question_relevance.append(
{
"question": queries[i]["questions"][q_index], # text version of question
"chunk": queries[i]["chunk"], # text version of chunk
"score": chunk_sim / other_sim, # relative similarity score
}
)
After we score each question by its relative relevancy, we can evaluate the generated questions as a whole.
[ ]:
# score above 1 means it is more relevant to its chunk than other chunks in the document (relative relevance). This shows that most chunks are relatively relevant.
scores = [x["score"] for x in question_relevance]
plt.hist(scores, bins=40);
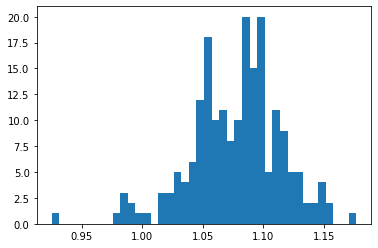
There are a couple scores that are less than 1, lets take a look at those.
[ ]:
for question_evaluation in [x for x in question_relevance if x["score"] < 1]:
print("Chunk:", question_evaluation["chunk"])
print("Question:", question_evaluation["question"])
print("Score:", question_evaluation["score"])
print("-" * 80) # delimiter
Manual verification of these “irrelevant” questions demonstrate that they do refer to the chunk but are vague or doesn’t align with the main focus. Hence, we can choose to filter these as desired.