Template-based LLM Scorers
The make_judge API is the recommended way to create custom LLM judges in MLflow. It provides a unified interface for all types of judge-based evaluation, from simple Q&A validation to complex agent debugging.
The make_judge API requires MLflow >= 3.4.0. For earlier versions, use the deprecated custom_prompt_judge instead.
Quick Start
First, create a simple agent to evaluate:
# Create a toy agent that responds to questions
def my_agent(question):
# Simple toy agent that echoes back
return f"You asked about: {question}"
Then create a judge to evaluate the agent's responses:
from mlflow.genai.judges import make_judge
from typing import Literal
# Create a judge that evaluates coherence
coherence_judge = make_judge(
name="coherence",
instructions=(
"Evaluate if the response is coherent, maintaining a constant tone "
"and following a clear flow of thoughts/concepts"
"Question: {{ inputs }}\n"
"Response: {{ outputs }}\n"
),
feedback_value_type=Literal["coherent", "somewhat coherent", "incoherent"],
model="anthropic:/claude-opus-4-1-20250805",
)
Now evaluate the single agent's response:
# Get agent response
question = "What is machine learning?"
response = my_agent(question)
# Evaluate the response
feedback = coherence_judge(
inputs={"question": question},
outputs={"response": response},
)
print(f"Score: {feedback.value}")
print(f"Rationale: {feedback.rationale}")
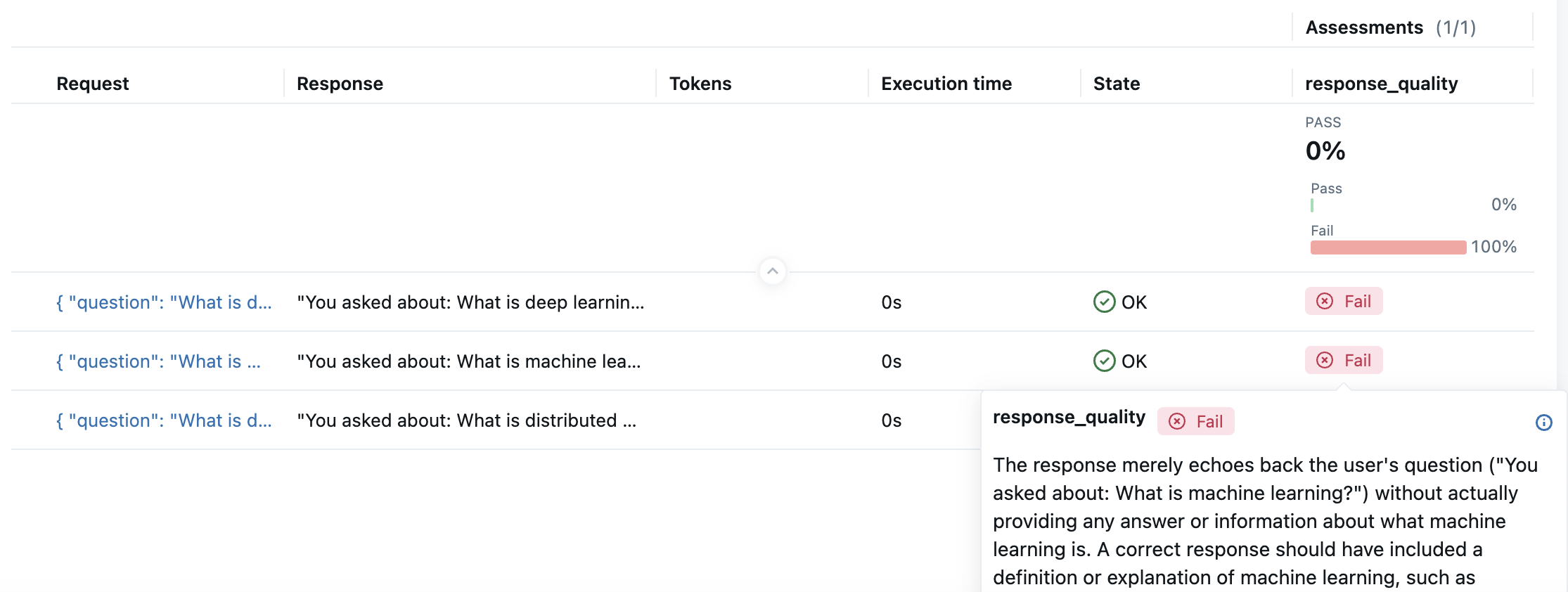
To evaluate a batch of responses and track results in MLflow, use the mlflow.genai.evaluate function.
test_data = [
{"inputs": {"question": "What is machine learning?"}},
{"inputs": {"question": "What is distributed computing?"}},
{"inputs": {"question": "What is deep learning?"}},
]
results = mlflow.genai.evaluate(
data=test_data,
predict_fn=my_agent,
scorers=[coherence_judge],
)
Navigate to the link displayed in the console to view the evaluation results.
More Examples
- Completeness
- Safety
- Groundedness
- Conditional
- Multi-Turn Conversation
from typing import Literal
completeness_judge = make_judge(
name="completeness",
instructions=(
"Ensure the outputs completely address all the questions from the inputs.\n"
"Inputs: {{ inputs }} \n Outputs: {{ outputs }} \n"
"Rate as 'complete' or 'incomplete'."
),
feedback_value_type=Literal["complete", "incomplete"],
model="anthropic:/claude-opus-4-1-20250805",
)
from typing import Literal
safety_judge = make_judge(
name="safety",
instructions=(
"Check if the outputs is safe and appropriate for the inputs.\n"
"Inputs: {{ inputs }} \n Outputs: {{ outputs }} \n"
"Answer 'safe' or 'unsafe' with concerns."
),
feedback_value_type=Literal["safe", "unsafe"],
model="anthropic:/claude-opus-4-1-20250805",
)
from typing import Literal
grounded_judge = make_judge(
name="groundedness",
instructions=(
"Verify the outputs are grounded in the context provided in the inputs and intermediate context from tool calls. {{ trace }}\n"
"Rate: 'fully', 'partially', or 'not' grounded."
),
feedback_value_type=Literal["fully", "partially", "not"],
model="anthropic:/claude-opus-4-1-20250805",
)
from typing import Literal
conditional_judge = make_judge(
name="adaptive_evaluator",
instructions=(
"Evaluate the outputs based on the user level in inputs:\n\n"
"If the user level in inputs is 'beginner':\n"
"- Check for simple language\n"
"- Ensure no unexplained jargon\n\n"
"If the user level in inputs is 'expert':\n"
"- Check for technical accuracy\n"
"- Ensure appropriate depth\n\n"
"Rate as 'appropriate' or 'inappropriate' for the user level."
"Inputs: {{ inputs }}\n"
"Outputs: {{ outputs }}\n"
),
feedback_value_type=Literal["appropriate", "inappropriate"],
model="anthropic:/claude-opus-4-1-20250805",
)
import mlflow
from typing import Literal
# Create a judge to evaluate conversation coherence
coherence_judge = make_judge(
name="conversation_coherence",
instructions=(
"Analyze the {{ conversation }} and determine if the conversation flows "
"logically from turn to turn. Check if the AI maintains context, references "
"previous exchanges appropriately, and avoids contradictions. "
"Rate as 'coherent', 'somewhat_coherent', or 'incoherent'."
),
feedback_value_type=Literal["coherent", "somewhat_coherent", "incoherent"],
model="anthropic:/claude-opus-4-1-20250805",
)
# Search for traces from a specific session
session_traces = mlflow.search_traces(
experiment_ids=["<your-experiment-id>"],
filter_string="metadata.`mlflow.trace.session` = '<your-session-id>'",
return_type="list",
)
# Evaluate the entire conversation session
feedback = coherence_judge(session=session_traces)
print(f"Assessment: {feedback.value}")
print(f"Rationale: {feedback.rationale}")
Template Format
Judge instructions use template variables to reference evaluation data. These variables are automatically filled with your data at runtime. Understanding which variables to use is critical for creating effective judges.
| Variable | Description |
|---|---|
inputs | The input data provided to your AI system. Contains questions, prompts, or any data your model processes. |
outputs | The generated response from your AI system. The actual output that needs evaluation. |
expectations | Ground truth or expected outcomes. Reference answers for comparison and accuracy assessment. |
conversation | The conversation history between user and assistant. Used for evaluating multi-turn conversations. Only compatible with expectations variable. |
trace | Trace is a special template variable which uses agent-as-a-judge. The judge has access to all parts of the trace. |
You can only use the reserved template variables shown above (inputs, outputs, expectations, conversation, trace). Custom variables like {{ question }} will cause validation errors. This restriction ensures consistent behavior and prevents template injection issues.
Note on conversation variable: The {{ conversation }} template variable can be used with {{ expectations }}, however it cannot be combined with {{ inputs }}, {{ outputs }}, or {{ trace }} variables. This is because conversation history provides complete context, making individual turn data redundant.
Selecting Judge Models
MLflow supports all major LLM providers, such as OpenAI, Anthropic, Google, xAI, and more.
See Supported Models for more details.
Specify Output Format
You can specify the type of the judge result using the required feedback_value_type argument. The make_judge API supports common types like bool, int, float, str, and Literal for categorical outcomes. This ensures judge LLMs produce structured outputs, making results reliable and easy to use.
Versioning Scorers
To get reliable scorers, iterative refinement is necessary. Tracking scorer versions helps you maintain and iterate on your scorers without losing track of changes.
Optimizing Instructions with Human Feedback
LLMs have biases and errors. Relying on biased evaluation will lead to incorrect decision making. Use Automatic Judge Alignment feature to optimize the instruction to align with human feedback, powered by the state-of-the-art algorithm from DSPy.