Tracing FireworksAI
FireworksAI is an inference and customization engine for open source AI. It provides day zero access to the latest SOTA OSS models and allows developers to build lightning AI applications.
MLflow Tracing provides automatic tracing capability for FireworksAI through the OpenAI SDK compatibility. FireworksAI is OpenAI SDK compatible, you can use the mlflow.openai.autolog() function to enable automatic tracing. MLflow will capture traces for LLM invocations and log them to the active MLflow Experiment.
MLflow automatically captures the following information about FireworksAI calls:
- Prompts and completion responses
- Latencies
- Model name
- Additional metadata such as
temperature,max_completion_tokens, if specified - Tool Use if returned in the response
- Any exception if raised
Getting Started
Install Dependencies
- Python
- JS / TS
pip install 'mlflow[genai]' openai
npm install mlflow-openai openai
Start MLflow Server
- Local (pip)
- Local (docker)
If you have a local Python environment >= 3.10, you can start the MLflow server locally using the mlflow CLI command.
mlflow server
MLflow also provides a Docker Compose file to start a local MLflow server with a postgres database and a minio server.
git clone --depth 1 --filter=blob:none --sparse https://github.com/mlflow/mlflow.git
cd mlflow
git sparse-checkout set docker-compose
cd docker-compose
cp .env.dev.example .env
docker compose up -d
Refer to the instruction for more details, e.g., overriding the default environment variables.
Enable Tracing and Make API Calls
- Python
- JS / TS
Enable tracing with mlflow.openai.autolog() and make API calls as usual.
import mlflow
import openai
import os
# Enable auto-tracing for FireworksAI (uses OpenAI SDK compatibility)
mlflow.openai.autolog()
# Set a tracking URI and an experiment
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("FireworksAI")
# Create an OpenAI client configured for FireworksAI
client = openai.OpenAI(
base_url="https://api.fireworks.ai/inference/v1",
api_key=os.getenv("FIREWORKS_API_KEY"),
)
# Use the client as usual - traces will be automatically captured
response = client.chat.completions.create(
model="accounts/fireworks/models/deepseek-v3-0324", # For other models see: https://fireworks.ai/models
messages=[
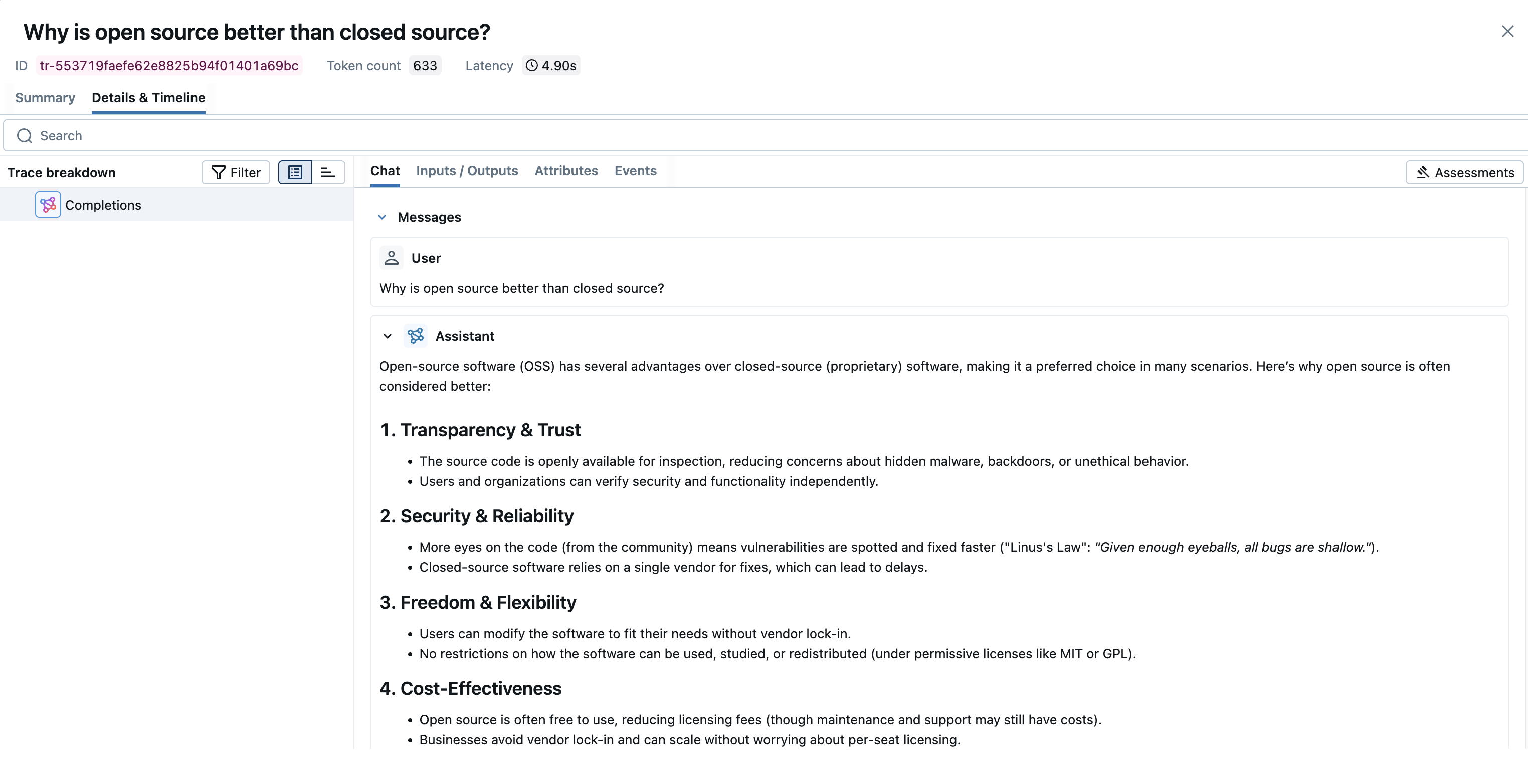
{"role": "user", "content": "Why is open source better than closed source?"}
],
)
Wrap the OpenAI client with the tracedOpenAI function and make API calls as usual.
import { OpenAI } from "openai";
import { tracedOpenAI } from "mlflow-openai";
// Wrap the OpenAI client and point to FireworksAI endpoint
const client = tracedOpenAI(
new OpenAI({
baseURL: "https://api.fireworks.ai/inference/v1",
apiKey: process.env.FIREWORKS_API_KEY,
})
);
// Use the client as usual - traces will be automatically captured
const response = await client.chat.completions.create({
model: "accounts/fireworks/models/deepseek-v3-0324", // For other models see: https://fireworks.ai/models
messages: [
{ role: "user", content: "Why is open source better than closed source?" }
],
});
View Traces in MLflow UI
Browse to the MLflow UI at http://localhost:5000 (or your MLflow server URL) and you should see the traces for the FireworksAI API calls.
→ View Next Steps for learning about more MLflow features like user feedback tracking, prompt management, and evaluation.
Supported APIs
Since FireworksAI is OpenAI SDK compatible, all APIs supported by MLflow's OpenAI integration work seamlessly with FireworksAI. See the model library for a list of available models on FireworksAI.
| Normal | Tool Use | Structured Outputs | Streaming | Async |
|---|---|---|---|---|
| ✅ | ✅ | ✅ | ✅ | ✅ |
Chat Completion API Examples
- Basic Example
- JS / TS
- Streaming
- Async
- Tool Use
import openai
import mlflow
import os
# Enable auto-tracing
mlflow.openai.autolog()
# Optional: Set a tracking URI and an experiment
# If running locally you can start a server with: `mlflow server --host 127.0.0.1 --port 5000`
mlflow.set_tracking_uri("http://127.0.0.1:5000")
mlflow.set_experiment("FireworksAI")
# Configure OpenAI client for FireworksAI
openai_client = openai.OpenAI(
base_url="https://api.fireworks.ai/inference/v1",
api_key=os.getenv("FIREWORKS_API_KEY"),
)
messages = [
{
"role": "user",
"content": "What is the capital of France?",
}
]
# To use different models check out the model library at: https://fireworks.ai/models
response = openai_client.chat.completions.create(
model="accounts/fireworks/models/deepseek-v3-0324",
messages=messages,
max_completion_tokens=100,
)
import { OpenAI } from "openai";
import { tracedOpenAI } from "mlflow-openai";
// Configure OpenAI client for FireworksAI
const client = tracedOpenAI(
new OpenAI({
baseURL: "https://api.fireworks.ai/inference/v1",
apiKey: process.env.FIREWORKS_API_KEY,
})
);
const messages = [
{
role: "user",
content: "What is the capital of France?",
}
];
// To use different models check out the model library at: https://fireworks.ai/models
const response = await client.chat.completions.create({
model: "accounts/fireworks/models/deepseek-v3-0324",
messages: messages,
max_tokens: 100,
});
console.log(response.choices[0].message.content);
MLflow Tracing supports streaming API outputs of FireworksAI endpoints through the OpenAI SDK. With the same setup of auto tracing, MLflow automatically traces the streaming response and renders the concatenated output in the span UI. The actual chunks in the response stream can be found in the Event tab as well.
import openai
import mlflow
import os
# Enable trace logging
mlflow.openai.autolog()
client = openai.OpenAI(
base_url="https://api.fireworks.ai/inference/v1",
api_key=os.getenv("FIREWORKS_API_KEY"),
)
stream = client.chat.completions.create(
model="accounts/fireworks/models/deepseek-v3-0324",
messages=[
{"role": "user", "content": "How fast would a glass of water freeze on Titan?"}
],
stream=True, # Enable streaming response
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="")
MLflow Tracing supports asynchronous API returns of FireworksAI through the OpenAI SDK. The usage is the same as the synchronous API.
import openai
import mlflow
import os
# Enable trace logging
mlflow.openai.autolog()
client = openai.AsyncOpenAI(
base_url="https://api.fireworks.ai/inference/v1",
api_key=os.getenv("FIREWORKS_API_KEY"),
)
response = await client.chat.completions.create(
model="accounts/fireworks/models/deepseek-v3-0324",
messages=[{"role": "user", "content": "What is the best open source LLM?"}],
# Async streaming is also supported
# stream=True
)
MLflow Tracing automatically captures tool use responses from FireworksAI models. The function instruction in the response will be highlighted in the trace UI. Moreover, you can annotate the tool function with the @mlflow.trace decorator to create a span for the tool execution.
The following example implements a simple tool use agent using FireworksAI and MLflow Tracing:
import json
from openai import OpenAI
import mlflow
from mlflow.entities import SpanType
import os
client = OpenAI(
base_url="https://api.fireworks.ai/inference/v1",
api_key=os.getenv("FIREWORKS_API_KEY"),
)
# Define the tool function. Decorate it with `@mlflow.trace` to create a span for its execution.
@mlflow.trace(span_type=SpanType.TOOL)
def get_weather(city: str) -> str:
if city == "Tokyo":
return "sunny"
elif city == "Paris":
return "rainy"
return "unknown"
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}},
},
},
}
]
_tool_functions = {"get_weather": get_weather}
# Define a simple tool calling agent
@mlflow.trace(span_type=SpanType.AGENT)
def run_tool_agent(question: str):
messages = [{"role": "user", "content": question}]
# Invoke the model with the given question and available tools
response = client.chat.completions.create(
model="accounts/fireworks/models/gpt-oss-20b",
messages=messages,
tools=tools,
)
ai_msg = response.choices[0].message
messages.append(ai_msg)
# If the model requests tool call(s), invoke the function with the specified arguments
if tool_calls := ai_msg.tool_calls:
for tool_call in tool_calls:
function_name = tool_call.function.name
if tool_func := _tool_functions.get(function_name):
args = json.loads(tool_call.function.arguments)
tool_result = tool_func(**args)
else:
raise RuntimeError("An invalid tool is returned from the assistant!")
messages.append(
{
"role": "tool",
"tool_call_id": tool_call.id,
"content": tool_result,
}
)
# Send the tool results to the model and get a new response
response = client.chat.completions.create(
model="accounts/fireworks/models/llama-v3p1-8b-instruct", messages=messages
)
return response.choices[0].message.content
# Run the tool calling agent
question = "What's the weather like in Paris today?"
answer = run_tool_agent(question)
Tracking Token Usage and Cost
MLflow automatically tracks token usage and cost for FireworksAI. The token usage for each LLM call will be logged in each Trace/Span and the aggregated cost and time trend are displayed in the built-in dashboard. See the Token Usage and Cost Tracking documentation for details on accessing this information programmatically.
Disable auto-tracing
Auto tracing for FireworksAI can be disabled globally by calling mlflow.openai.autolog(disable=True) or mlflow.autolog(disable=True).
Next steps
Track User Feedback
Record user feedback on traces for tracking user satisfaction.
Manage Prompts
Learn how to manage prompts with MLflow's prompt registry.
Evaluate Traces
Evaluate traces with LLM judges to understand and improve your AI application's behavior.