Tracing Semantic Kernel
Semantic Kernel is a lightweight, open-source SDK that functions as AI middleware, enabling you to integrate AI models into your C#, Python, or Java codebase via a uniform API layer. By abstracting model interactions, it lets you swap in new models without rewriting your application logic.
MLflow Tracing provides automatic tracing capability for Semantic Kernel. By enabling auto tracing for Semantic Kernel via the mlflow.semantic_kernel.autolog() function, MLflow will capture traces for LLM invocations and log them to the active MLflow Experiment.
MLflow trace automatically captures the following information about Semantic Kernel calls:
- Prompts and completion responses
- Chat history and messages
- Latencies
- Model name and provider
- Kernel functions and plugins
- Template variables and arguments
- Token usage information
- Any exceptions if raised
Currently, tracing for streaming is not supported. If you want this feature, please file a feature request.
Getting Started
To get started, let's install the requisite libraries. Note that we will use OpenAI for demonstration purposes, but this tutorial extends to all providers supported by Semantic Kernel.
pip install 'mlflow[genai]>=3.2.0' semantic_kernel openai
Then, enable autologging in your Python code:
You must run mlflow.semantic_kernel.autolog() prior to running Semantic Kernel code. If this is not performed, traces may not be logged properly.
import mlflow
mlflow.semantic_kernel.autolog()
Finally, for setup, let's establish our OpenAI token:
import os
from getpass import getpass
# Set the OpenAI API key as an environment variable
os.environ["OPENAI_API_KEY"] = getpass("openai_api_key: ")
Example Usage
Semantic Kernel primarily uses asynchronous programming patterns. The examples below use async/await syntax. If you're running these in a Jupyter notebook, the code will work as-is. For scripts, you'll need to wrap the async calls appropriately (e.g., using asyncio.run()).
The simplest example to show the tracing integration is to instrument a ChatCompletion Kernel.
import openai
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
from semantic_kernel.functions.function_result import FunctionResult
# Create a basic OpenAI client
openai_client = openai.AsyncOpenAI()
# Create a Semantic Kernel instance and register the OpenAI chat completion service
kernel = Kernel()
kernel.add_service(
OpenAIChatCompletion(
service_id="chat-gpt",
ai_model_id="gpt-4o-mini",
async_client=openai_client,
)
)
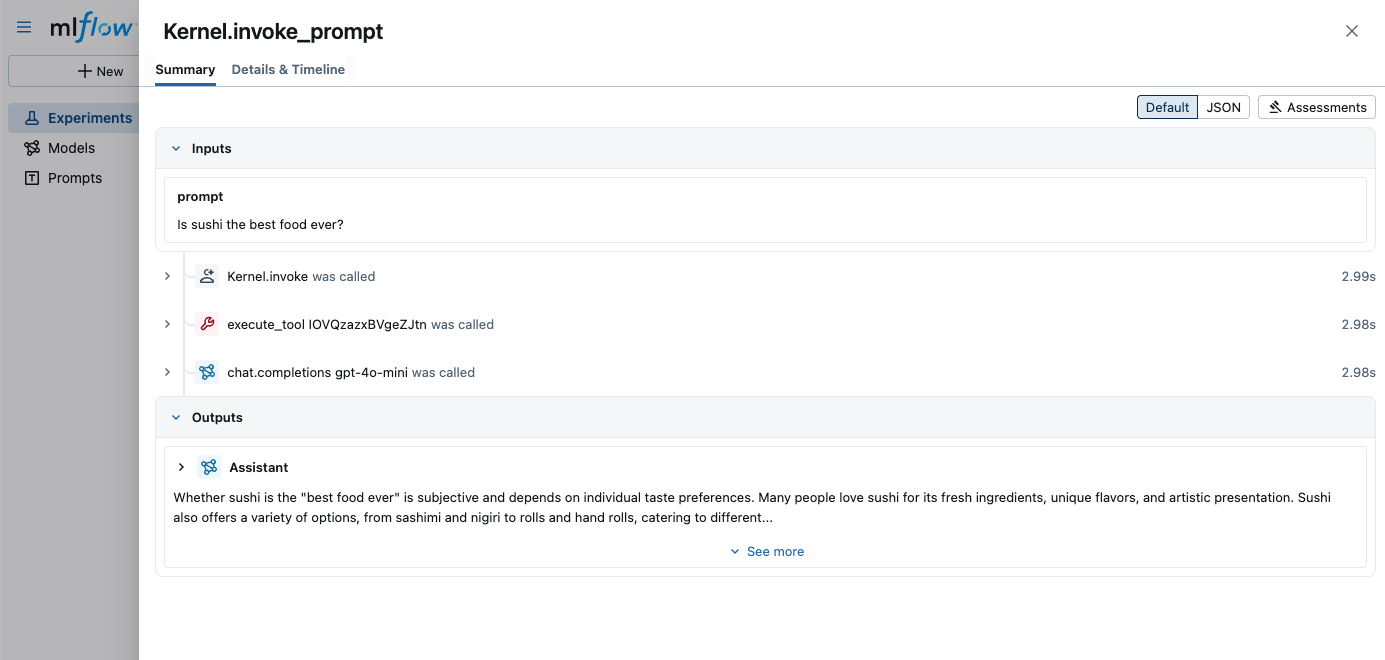
answer = await kernel.invoke_prompt("Is sushi the best food ever?")
print("AI says:", answer)
Tracking Token Usage and Cost
MLflow automatically tracks token usage and cost for Semantic Kernel. The token usage for each LLM call will be logged in each Trace/Span and the aggregated cost and time trend are displayed in the built-in dashboard. See the Token Usage and Cost Tracking documentation for details on accessing this information programmatically.
Disable Auto-tracing
Auto tracing for Semantic Kernel can be disabled globally by calling mlflow.semantic_kernel.autolog(disable=True) or mlflow.autolog(disable=True).