LLM Evaluation and Agent Evaluation
LLM evaluation systematically measures the quality of LLM applications across dimensions like correctness, relevance, safety, and coherence. Agent evaluation extends LLM evaluation to also assess multi-step reasoning, tool selection, task completion, and beyond for autonomous agents.
Evaluation gives engineering teams confidence that their agents and LLM applications actually work well: not just whether they run, but whether they produce correct, safe, and useful results. As agents move from prototypes to production-critical applications, evaluation becomes essential for maintaining quality and enabling continuous improvement.
Unlike traditional software, agents and LLM applications are non-deterministic: the same input can produce different outputs. This makes exact-match testing insufficient. AI evaluation uses LLM judges, human feedback, and code-based metrics to assess quality dimensions like correctness, relevance, safety, and helpfulness across representative datasets.
Quick Navigation:
Why LLM and Agent Evaluation Matters
Agents, LLM applications, and RAG systems introduce unique challenges that traditional software testing can't address:
Quality Assurance
Problem: Agent outputs are non-deterministic and can include hallucinations or irrelevant responses.
Solution: Automated LLM judges continuously assess quality dimensions like correctness, relevance, and safety across every response.
Regression Detection
Problem: Prompt changes, model updates, or data drift can silently degrade quality without obvious errors.
Solution: Run evaluations against benchmark datasets before deployment and continuously in production to catch regressions early.
Agent Debugging
Problem: Multi-step agents make complex decisions about tool use, data access, and control flow that are hard to understand and debug.
Solution: Evaluate agent trajectories end-to-end, assessing tool selection accuracy, reasoning quality, and task completion.
Safety & Compliance
Problem: Agents can produce harmful, off-topic, or policy-violating outputs that are hard to catch with static rules.
Solution: Use LLM judges to assess safety, toxicity, and policy compliance across every response.
LLM Evaluation
LLM evaluation focuses on measuring the quality of outputs from large language models and LLM-powered applications. This includes assessing whether responses are accurate, relevant to the user's question, grounded in provided context, free from harmful content, and helpful for the user's goals.
For single-turn LLM applications (content generators, summarization tools, translation, classification), evaluation helps you understand which prompts produce the best results, identify quality issues before they reach users, and track quality over time. LLM judges automate this assessment, enabling evaluation at scale without requiring human review of every response.
MLflow's evaluation framework provides built-in judges for common quality dimensions (safety, correctness, relevance, groundedness) and APIs to create custom judges tailored to your specific requirements and domain expertise.
Agent Evaluation
Agent evaluation extends LLM evaluation to multi-step agentic systems. While LLM evaluation assesses individual responses, agent evaluation must assess the complete trajectory: how agents reason about tasks, which tools they select, how they handle errors, and whether they achieve their goals efficiently.
Agents built with frameworks like LangGraph, CrewAI, ADK, or Pydantic AI can behave unpredictably: getting stuck in loops, making incorrect tool choices, or producing inconsistent outputs across runs. Agent evaluation captures the full execution graph, enabling you to assess whether the agent chose the right tools, used them with correct arguments, recovered gracefully from errors, and completed objectives efficiently.
MLflow supports agent evaluation through trajectory-based scorers that assess the complete agent path, not just the final answer. Combined with tracing that captures every step, you can debug agent failures, optimize prompts and tool selection logic, and build confidence that agents behave correctly in production.
LLM Evaluation vs Agent Evaluation: Key Differences
Understanding the distinction between agent evaluation and LLM evaluation is critical for choosing the right evaluation strategy. While they share common foundations, they differ significantly in scope, metrics, and complexity.
| Aspect | LLM Evaluation | Agent Evaluation |
|---|---|---|
| Scope | Single input/output pair | Multi-step trajectory with tool calls |
| What You Evaluate | Response quality only | Reasoning + tool use + final outcome |
| Key Metrics | Correctness, relevance, safety, fluency | Tool call accuracy, task completion, efficiency, error recovery |
| Typical Use Cases | Summarization, translation, single-turn Q&A, content generation, classification | Chatbots, autonomous assistants, coding agents, RAG systems, research agents, workflow automation |
| Failure Modes | Hallucinations, irrelevance, unsafe content | Infinite loops, wrong tool selection, incomplete goals, inefficient paths |
| MLflow Scorers | Safety, Correctness, RelevanceToQuery, Groundedness | ToolCallEfficiency, RoleAdherence, ConversationalSafety, custom trajectory scorers |
The Evaluation Lifecycle
Agent and LLM evaluation isn't a one-time activity. It's a continuous cycle that spans the entire development and deployment process. Here's how evaluation fits into each stage:
Common Use Cases for AI Evaluation
AI evaluation solves real-world problems across the AI development lifecycle:
- Pre-deployment Testing: Before releasing new prompts, models, or agent logic, run comprehensive evaluations against benchmark datasets. Compare quality metrics to previous versions to ensure changes improve, not degrade, your application.
- Continuous Quality Monitoring: In production, continuously evaluate responses with automated judges to detect quality regressions, emerging failure patterns, or drift from expected behavior before users notice.
- Debugging Failures: When your agent or LLM application produces incorrect outputs, evaluation pinpoints the root cause. Was the retrieval poor? The reasoning flawed? The tool selection wrong? Evaluation results combined with traces reveal exactly what went wrong.
- A/B Testing Prompt Changes: Before deploying prompt modifications to production, run side-by-side evaluations with LLM judges. Compare quality metrics to ensure changes improve output quality, or use prompt optimization to automate the improvement process entirely.
- Building Regression Datasets: Convert production failures and edge cases into evaluation examples. Over time, build a comprehensive regression dataset that catches known failure modes before they reach production again.
- Safety and Compliance: Use safety scorers to detect harmful, biased, or policy-violating outputs. Maintain audit trails of evaluation results for regulatory compliance and incident investigation.
Key Components of AI Evaluation
A comprehensive AI evaluation platform combines six capabilities:
- LLM Judges: Automated scorers that use language models to assess output quality across dimensions like correctness, relevance, safety, and helpfulness.
- Custom Scorers: Code-based metrics using Python functions for deterministic checks like format validation, length limits, and regex patterns.
- Evaluation Datasets: Curated sets of test cases with inputs and optional expected outputs that represent your application's typical usage and edge cases.
- Evaluation UI: Visual interface to review results, compare versions, and drill into individual examples to understand failures.
- Tracing Integration: Evaluate production traces to monitor quality continuously and debug failures with full execution context.
- Human Feedback: Collect expert reviews and end-user ratings to validate LLM judges and identify blind spots in automated evaluation.
How to Implement Agent Evaluation
Modern open-source AI platforms like MLflow make it easy to add comprehensive evaluation to your agents and LLM applications with minimal code.
With just a few lines of code, you can evaluate your application against datasets using built-in or custom scorers. Results are tracked in MLflow, where you can compare versions, drill into failures, collect human feedback, and monitor quality over time. You can evaluate during development (testing new prompts), before deployment (comprehensive benchmark testing), and in production (continuous monitoring).
Here are quick examples of evaluating with MLflow. Check out the MLflow evaluation documentation for comprehensive guides and framework-specific examples.
Evaluation with Built-in Judges
import mlflowfrom mlflow.genai.scorers import Safety, Correctness, RelevanceToQuery# Evaluate your agent or LLM applicationresults = mlflow.genai.evaluate(data="my_eval_dataset", # Your evaluation datasetpredict_fn=my_agent, # Your agent or LLM appscorers=[Safety(), # Check for harmful contentCorrectness(), # Check factual accuracyRelevanceToQuery(), # Check response relevance],)# View results in MLflow UI or programmaticallyprint(f"Safety pass rate: {results.metrics['safety/pass_rate']}")print(f"Correctness pass rate: {results.metrics['correctness/pass_rate']}")
Evaluation with Custom LLM Judges
from mlflow.genai.judges import make_judgefrom typing import Literal# Create a custom judge for your specific criteriaconversation_quality_judge = make_judge(name="conversation_quality",instructions=("Analyze the {{ conversation }} for signs of user frustration, ""unresolved questions, incomplete answers, or factual errors. ""Consider the full context of the interaction."),feedback_value_type=Literal["high_quality", "medium_quality", "low_quality"],)# Use in evaluationresults = mlflow.genai.evaluate(data=eval_data,scorers=[conversation_quality_judge],)
Evaluation with Custom Code-based Metrics
from mlflow.genai.scorers import scorer@scorerdef response_length(inputs, outputs):"""Check response is within acceptable length limits."""word_count = len(outputs["response"].split())return {"score": 50 <= word_count <= 500,"rationale": f"Response has {word_count} words",}@scorerdef contains_required_sections(inputs, outputs):"""Check response includes all required sections."""response = outputs["response"].lower()required = ["summary", "recommendation", "next steps"]missing = [s for s in required if s not in response]return {"score": len(missing) == 0,"rationale": f"Missing sections: {missing}" if missing else "All sections present",}# Use in evaluationresults = mlflow.genai.evaluate(data=traces_to_evaluate,scorers=[response_length, contains_required_sections],)
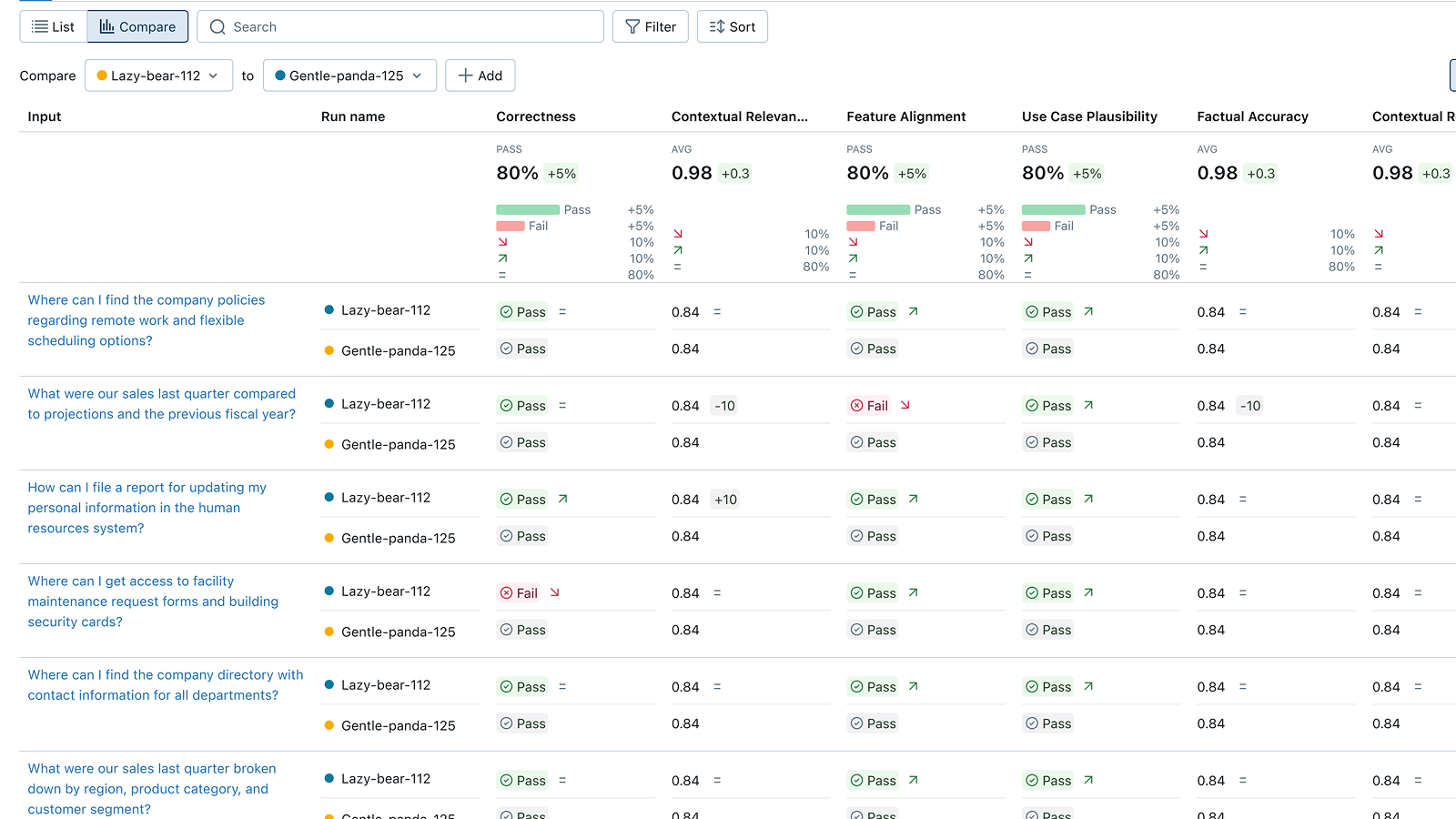
The MLflow Evaluation UI displays results, enabling version comparison and failure analysis
MLflow is the largest open-source AI engineering platform for agents, LLMs, and ML models, with over 30 million monthly downloads. Thousands of organizations use MLflow to debug, evaluate, monitor, and optimize production-quality AI agents and LLM applications while controlling costs and managing access to models and data. Backed by the Linux Foundation and licensed under Apache 2.0, MLflow provides a complete evaluation solution with no vendor lock-in. Get started →
Open Source vs. Proprietary Evaluation Tools
When choosing an AI evaluation platform, the decision between open source and proprietary SaaS tools has significant long-term implications for your team, infrastructure, and data ownership.
Open Source (MLflow): With MLflow, you maintain complete control over your evaluation infrastructure and data. Deploy on your own infrastructure or use managed versions on Databricks, AWS, or other platforms. There are no per-evaluation fees, no usage limits, and no vendor lock-in. Your evaluation data stays under your control, and you can customize judges and metrics to your exact needs.
Proprietary SaaS Tools: Commercial evaluation platforms offer convenience but at the cost of flexibility and control. They typically charge per evaluation or per seat, which can become expensive at scale. Your data is sent to their servers, raising privacy and compliance concerns. You're locked into their ecosystem, making it difficult to switch providers or customize functionality.
Why Teams Choose Open Source: Organizations building production agents increasingly choose MLflow because it offers enterprise-grade evaluation without compromising on data sovereignty, cost predictability, or flexibility. The Apache 2.0 license and Linux Foundation backing ensure MLflow remains truly open and community-driven, not controlled by a single vendor.