What is LLMOps?
LLMOps (LLM Operations) is the discipline of building, deploying, monitoring, and maintaining large language model applications in production. It encompasses the tools, practices, and workflows that teams need to move LLM-powered applications from prototype to production, including tracing, evaluation, prompt management, AI Gateways for governed model access, and production monitoring. For multi-step agentic systems, this is known as AgentOps.
As LLM applications evolve from single-turn chatbots to multi-step agents and RAG systems, the operational challenges grow significantly. LLMs are non-deterministic, expensive, and difficult to evaluate with traditional software testing. LLMOps gives teams the tools to manage these challenges, bringing the same structure to LLM applications that DevOps and MLOps brought to software and machine learning.
LLMOps platforms provide the tooling to address these challenges: tracing for debugging, LLM-as-a-judge evaluation for quality assurance, prompt registries for version control, AI gateways for governed model access, and production monitoring for catching regressions.
Why LLMOps Matters
LLM applications introduce unique operational challenges that traditional DevOps and MLOps can't address:
Non-Deterministic Outputs
Problem: The same prompt can produce different outputs across runs, making it impossible to test LLM applications with traditional assertions.
Solution: LLMOps uses automated evaluation with LLM judges to assess quality at scale, replacing brittle exact-match tests with semantic quality scoring.
Prompt Fragility
Problem: Small changes to prompts can dramatically alter output quality, and there's no built-in version control for prompt templates.
Solution: Prompt registries provide version control, A/B testing, and rollback capabilities for prompt templates, and prompt optimization automates improvement using training data.
Governance and Cost Controls
Problem: Teams lack centralized control over which models are used, how they're accessed, and what rate limits apply. Token costs can also spiral with multi-step agents making many LLM calls per request.
Solution: AI Gateways provide a single control plane for model access with rate limiting, authentication, fallback routing, and cost tracking. Tracing captures token usage and latency per span, making it easy to find expensive operations and debug unexpected behavior.
Complex Debugging
Problem: When agents fail, it's nearly impossible to understand why without visibility into every reasoning step, tool call, and retrieval.
Solution: End-to-end tracing makes every step visible and debuggable, from initial request through tool calls to final response.
From MLOps to LLMOps
Traditional MLOps focuses on training, validating, and deploying machine learning models. LLMOps addresses a different set of problems. LLM applications are driven by prompts rather than training data, their outputs are non-deterministic, and quality can't be measured with simple accuracy metrics. Agents add even more complexity: multi-step reasoning, tool calls, and autonomous decision-making all need to be traced, evaluated, and governed.
LLMOps is closely related to AIOps (the broader discipline of running all AI applications in production) and AI observability (the monitoring and debugging subset). LLMOps specifically targets LLM-powered applications, while AIOps also covers traditional ML experiment tracking and model management.
AgentOps
AgentOps extends LLMOps to multi-step agentic systems. While LLMOps covers single LLM calls and simple applications, AgentOps addresses the unique challenges of autonomous agents: tracing multi-step reasoning chains, debugging complex tool call sequences, evaluating agent decision-making, and monitoring workflows where agents make dozens of LLM calls per request.
AgentOps includes all LLMOps capabilities (tracing, evaluation, prompt management) plus agent-specific tooling: execution graph visualization to debug reasoning loops, agent evaluation with multi-turn testing, tool call correctness scoring, and optimization of agent workflows to reduce token costs and latency. MLflow provides complete AgentOps support for all agent frameworks, including LangGraph, CrewAI, Pydantic AI, Google ADK, and custom agent implementations.
Key Components of LLMOps
A production LLMOps workflow combines several capabilities:
- Tracing: Record every step of LLM and agent execution (prompts, completions, tool calls, retrieval results, token usage, and latency) for debugging and production monitoring.
- Evaluation: Assess output quality using LLM judges, custom scorers, and human feedback before and after deployment.
- Prompt Management: Version-control prompt templates, track which versions are in production, enable safe rollbacks when quality degrades, and run automated optimization.
- Production Monitoring: Track quality scores, error rates, costs, and latency over time with LLM judges to catch regressions early.
- AI Gateway: Route requests across LLM providers (OpenAI, Anthropic, Bedrock, etc.) through a single endpoint with unified authentication, rate limiting, and fallback routing.
- Governance & Safety: Maintain audit trails, enforce PII policies, and apply content guardrails across your LLM applications.
LLMOps with MLflow
MLflow is the only open-source, production-grade, end-to-end LLMOps platform. It supports any LLM, framework, and programming language, and is backed by the Linux Foundation. MLflow provides solutions for every layer of the LLMOps stack:
- MLflow Tracing — Auto-instrument any LLM framework in one line of code. Captures prompts, completions, tool calls, token usage, and latency for every request.
- MLflow LLM Evaluation — Score outputs with LLM judges, custom scorers, and human feedback. Built-in judges for correctness, safety, groundedness, and RAG quality.
- MLflow Prompt Registry — Version control, diff tracking, and aliases (dev, staging, production) for prompt templates. Edit in the UI without code changes.
- MLflow AI Gateway — Single control plane for model access across providers with governance, rate limiting, authentication, fallback routing, and cost tracking.
- MLflow Production Monitoring — Run LLM judges continuously against production traces to catch quality regressions before users report them.
- MLflow Agent Server — Deploy agents to production with built-in tracing, streaming, and request validation.
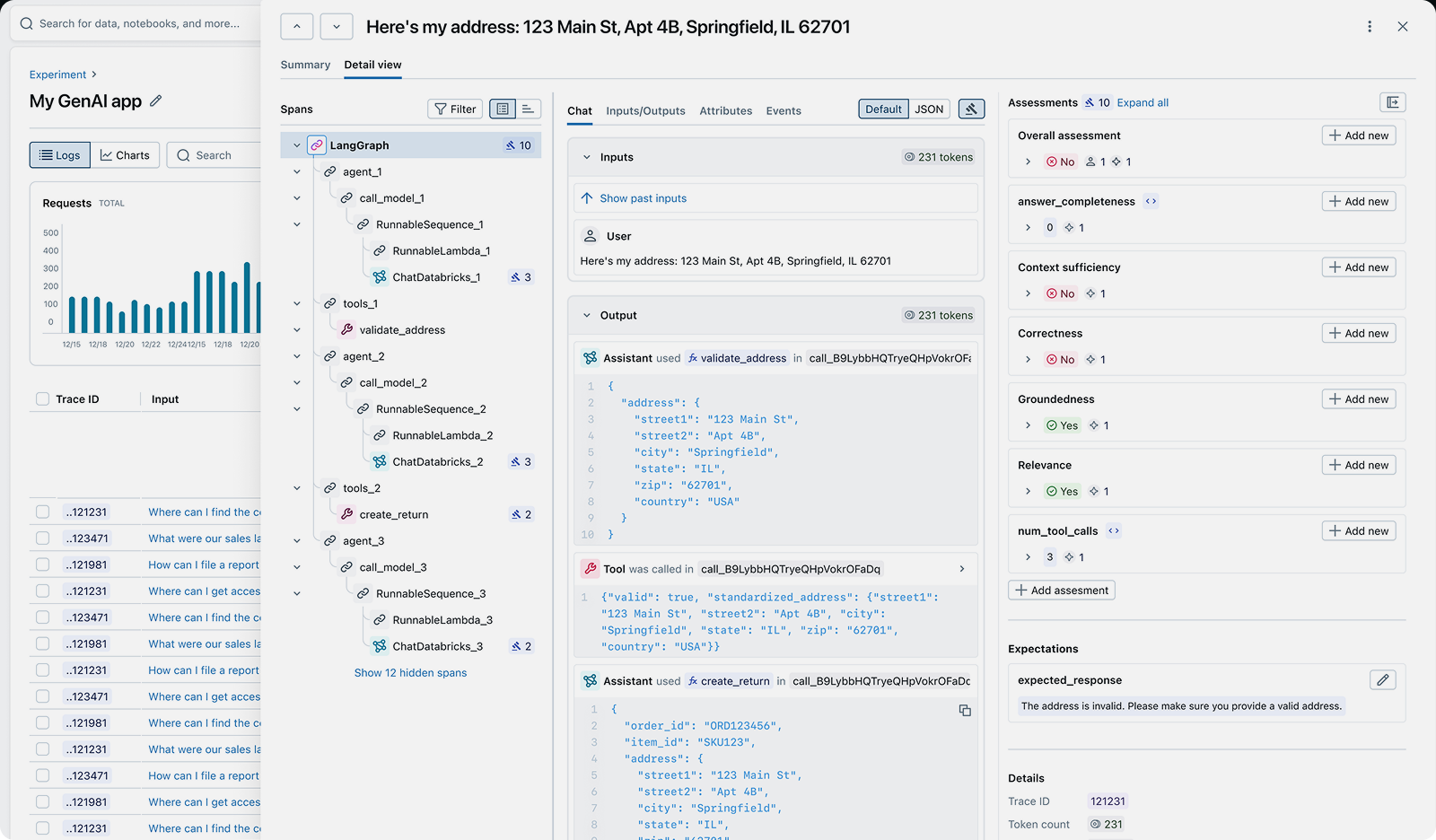
MLflow captures traces for every LLM call with full execution context
MLflow is the largest open-source AI engineering platform for agents, LLMs, and ML models, with over 30 million monthly downloads. Thousands of organizations use MLflow to debug, evaluate, monitor, and optimize production-quality AI agents and LLM applications while controlling costs and managing access to models and data. Backed by the Linux Foundation and licensed under Apache 2.0, MLflow provides a complete LLMOps stack with no vendor lock-in. Get started →
Open Source vs. Proprietary LLMOps
When choosing an LLMOps platform, the decision between open source and proprietary SaaS tools has significant long-term implications for your team, infrastructure, and data ownership.
Open Source (MLflow): With MLflow, you maintain complete control over your LLMOps infrastructure and data. Deploy on your own infrastructure or use managed versions on Databricks, AWS, or other platforms. There are no per-seat fees, no usage limits, and no vendor lock-in. MLflow integrates with any LLM provider and agent framework through OpenTelemetry-compatible tracing.
Proprietary SaaS Tools: Commercial LLMOps platforms offer convenience but at the cost of flexibility and control. They typically charge per seat or per trace volume, which can become expensive at scale. Your data is sent to their servers, raising privacy and compliance concerns. You're locked into their ecosystem, making it difficult to switch providers or customize functionality.
Why Teams Choose Open Source: Organizations building production LLM applications increasingly choose MLflow because it offers production-ready LLMOps without giving up control of their data, cost predictability, or flexibility. The Apache 2.0 license and Linux Foundation backing ensure MLflow remains truly open and community-driven.